Introduction: The Power of Simple Questions#
Imagine you are a doctor diagnosing a patient. You don’t run every test simultaneously. Instead, you ask a sequence of questions: “Does the patient have a fever?” If yes, you ask, “Is there a rash?” If no, you might ask, “Is the pain localized?” This hierarchical process of asking questions to narrow down possibilities is the very essence of a Decision Tree.
A Decision Tree is a non-parametric (no assumptions about data distribution or functional form, allowing them to learn patterns directly from the data), supervised learning algorithm used for both classification and regression tasks. Its model forms a tree-like structure, mimicking human decision-making processes.
Parameteric vs Non-Parametric: A Decision Tree (DT) is non-parametric, meaning it makes no assumptions about data distribution or functional form and has no fixed number of parameters—its complexity (splits, depth, etc.) adapts to the data; unlike parametric models (e.g., linear or logistic regression) that assume a specific functional form and have fixed parameters.
They mimic human decision-making by breaking down complex decisions into a series of simpler questions. A Decision Tree represents decisions in a flowchart-like, hierarchical structure that models possible consequences—including outcomes, costs, and probabilities and is highly interpretable.
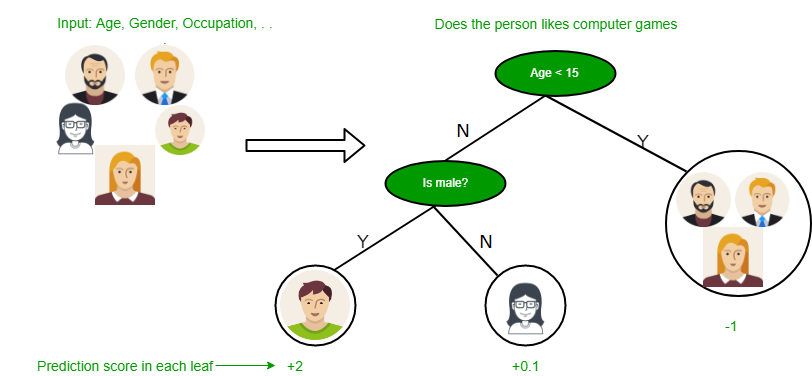
They are especially popular because they require minimal data preprocessing, can handle both numerical and categorical data, and provide models that are easily interpretable.
It has many strengths:
Interpretability: The resulting model is a white box. The rules for making a prediction can be easily understood and explained, even to non-experts.
Few Data Preprocessing Requirements: They require little data preparation (e.g., no need for feature scaling or normalization).
Handles Mixed Data Types: They can work with both numerical and categorical data.
Non-Linearity: They can capture complex non-linear relationships between features and the target variable.
However, this simplicity can also be a weakness because it often leads to overfitting. When a tree grows too deep, it starts to learn the noise in the training data, not just the underlying pattern, which causes poor performance on new data.
In this chapter, we will break down how the Decision Tree algorithm works, understand how to create good splitting questions, learn how to prune an overly complex tree, and see how Decision Trees serve as the foundation for advanced ensemble methods like Random Forests and Gradient Boosting Machines
Section 1: Basic Concepts of Decision Tree#
Next, we will learn some basic concepts related to decision tree.
Structure of a Decision Tree and Terminology#
To understand how a tree is built, we must first understand its components. A Decision Tree is a graph composed of:
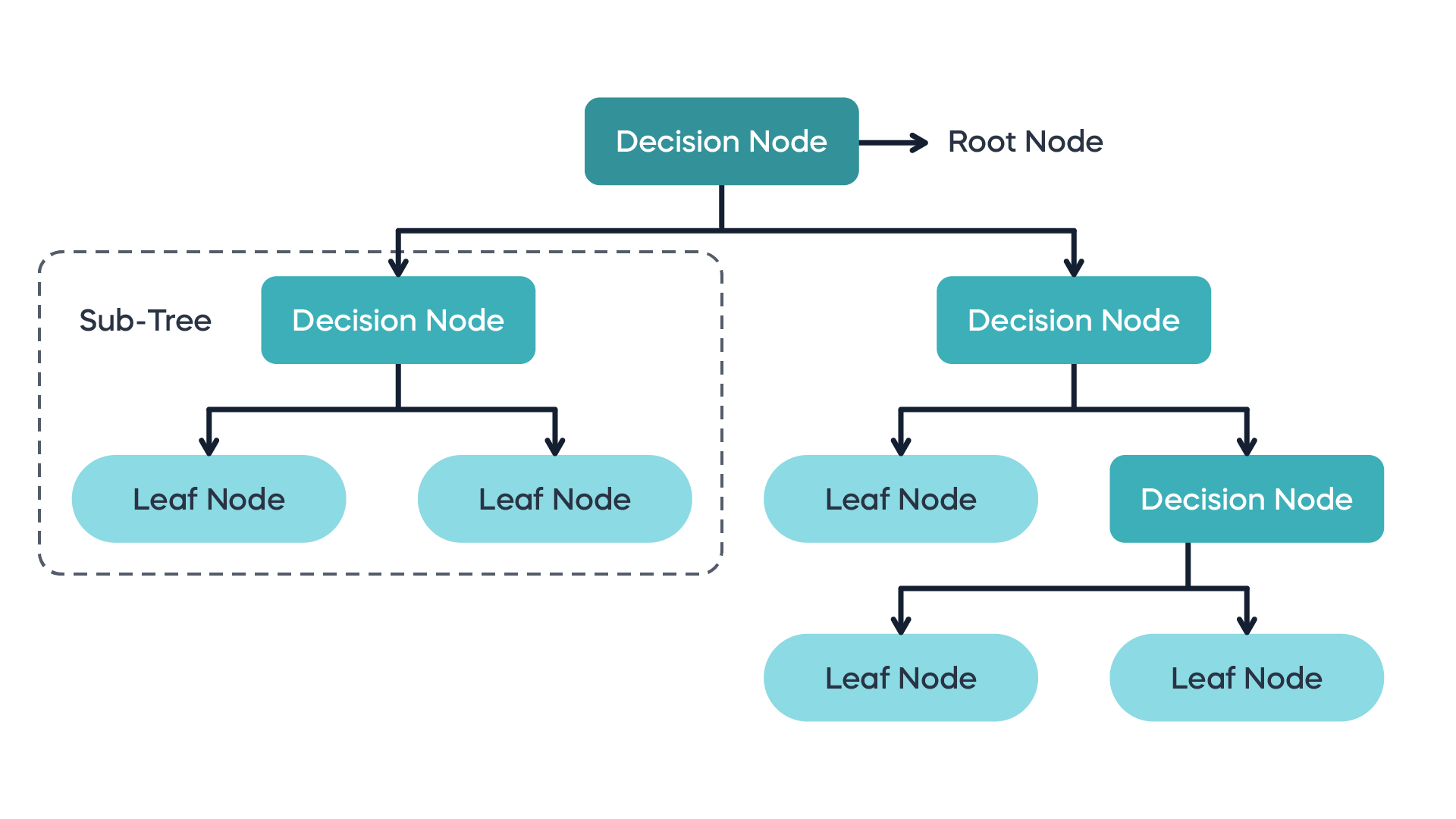
Root Node: The topmost node, representing the entire dataset. It is the starting point for the splitting process.
Internal Nodes (Decision Nodes): Nodes that represent a decision point or a test on a specific feature. Each internal node splits the data into two or more branches.
Branches (Edges): The outcome of a decision node test, leading to the next node.
Leaf Nodes (Terminal Nodes): The final nodes in the tree that do not split further. Each leaf node represents a class label (in classification) or a continuous value (in regression) which is the final prediction.
The path from the root to a leaf represents a series of conjunctions (AND operations) of the conditions at the internal nodes, forming a classification rule.
More Terminology#
Sub-Tree: A portion of the main tree.
Splitting: The process of dividing a node into two or more sub-nodes.
Pruning: The process of removing branches to reduce the complexity of the tree and prevent overfitting (we will talk about it later in this chapter).
Example#
Consider the classic “Play Tennis” dataset, where we want to predict whether to play tennis based on weather conditions (Outlook, Temperature, Humidity, Windy).
A simplified decision tree might look like:
