Chapter 6: Mastering SQL for Data Science with Python#
Walk into any online store, hospital, bank, or airline system and behind the scenes something is keeping track of who is who, what belongs to whom, and what has changed. A shopping cart remembers the items you chose. A reservation system checks seat availability. A bank records every transaction down to the cent. These systems run on structured data, and for decades that information has been organized using relational databases.
Relational databases were built for reliability and structure. Structured Query Language (SQL) became the language for interacting with them. Instead of telling the computer how to compute something step by step, SQL lets us say what we want: select certain columns, filter certain rows, or join two tables to complete the picture. It is declarative, expressive, and surprisingly good at describing real-world questions.
For data science, this matters because a large portion of the world’s structured data already lives in SQL warehouses. Many analyses begin not with modeling, but with asking for the right data: which customers, which time period, which features, and which tables. SQL is how we explore, filter, combine, and summarize before anything else; often before Pandas, visualization, or machine learning ever enter the pipeline.
The chapter introduces Structured Query Language (SQL), a powerful and essential tool for data professionals. we will learn how to use SQL to work with real data and how SQL integrates naturally with Python. By the end, the goal is not just to write SQL queries, but to think in SQL: to express questions clearly and retrieve the information needed to answer them; a crucial skill for any data scientist.
Introduction to SQL for Data Science#
Data has become the foundation of decision-making in modern organizations. From social media platforms storing billions of user interactions to hospitals managing electronic health records, most of this information is stored in databases. Among different types of databases, relational databases are the most widely used.
Relational databases organize data into tables, which consist of rows (records) and columns (attributes). This design reflects the way data naturally relates to entities in the real world. For example:
*A retail store has customers (with IDs, names, and ages).
Each customer places orders (with product details, dates, and amounts).
The relationship between customers and orders can be represented through keys.
To interact with these databases, we use a language called Structured Query Language (SQL).
Structured Query Language (SQL).#
SQL provides a standardized way to create, read, update, and delete data (commonly referred to as CRUD operations). Unlike programming languages such as Python or Java, SQL is declarative: you specify what you want, and the database figures out how to get it.
This makes it highly efficient for managing large datasets. For data science, SQL is invaluable for:
Data Retrieval: Extracting specific subsets of data from large databases.
Data Cleaning and Transformation: Handling missing values, standardizing formats, and creating new features.
Exploratory Data Analysis (EDA): Performing quick summaries, aggregations, and data profiling.
Feature Engineering: Creating new variables from existing ones before feeding them into machine learning models.
The Evolution of Databases and SQL#
Early data management: Before databases, organizations stored information in files. This approach led to redundancy, inconsistency, and inefficiency.
Birth of the relational model: In 1970, Edgar F. Codd introduced the relational model, a mathematical foundation for organizing data in tables with well-defined relationships.
Development of SQL: By the late 1970s, IBM developed SEQUEL (Structured English Query Language), which evolved into SQL. It became the ANSI standard in 1986.
SQL today: Almost every relational database system (MySQL, PostgreSQL, Oracle, SQL Server, SQLite) supports SQL, with minor dialect differences.
Takeaway: SQL is not just a programming tool; it is the backbone of modern data storage and analytics.
When to Use SQL and When to Use Pandas#
Data scientists switch between SQL and Pandas because they excel at different stages of the workflow.
SQL makes sense when the data lives in a database.
It offloads computation to the database engine, which is optimized for filtering, joining, and aggregating large datasets—often far bigger than a laptop can hold in memory. SQL is also ideal when multiple systems need consistent access to the same structured data.
Use SQL when:
data is stored in a relational database
the dataset is large (beyond local memory)
the main task is selecting, filtering, joining, or summarizing
consistency and shared access matter
Pandas shines once the data is local.
It enables fast, flexible manipulation: reshaping tables, enriching features, exploring distributions, and creating visualizations. Pandas works especially well in notebooks, where analysis is iterative and interactive.
Use Pandas when:
data arrives as CSV/Excel/JSON or via APIs and scraping
the task is cleaning, transforming, or feature engineering
visualization or modeling follows
custom logic is easier to express in Python
In practice, a common pipeline looks like:
Database → SQL → subset → Pandas → exploration / visualization / ML
SQL retrieves and trims; Pandas experiments and interprets.
Rule of thumb:
SQL for extracting structured data; Pandas for understanding and shaping it.
Relational Databases: Core Concepts#
Relational databases are the backbone of structured data storage. They organize information in a way that ensures consistency, integrity, and efficient retrieval. The fundamental ideas of tables, keys, and relationships help us understand how real-world data is modeled.
Tables, Rows, and Columns#
A table is like a spreadsheet.
Rows (records/tuples): Each row corresponds to a single entity or instance of data. For example, one row might represent a single customer.
Columns (fields/attributes): Each column stores one specific type of information about the entity, such as name, age, or gender.
Schema: The structure of the table, which defines what columns exist and their data types (e.g., integer, string, date).
Example: A Customers table may contain columns such as Customer_ID, Name, Age, Gender, and Email. Each row represents one customer.
Keys#
Keys in Relational Databases are crucial for ensuring that data remains unique and consistent across tables.
1. Primary Key (PK)#
The primary key uniquely identifies each row. It contain UNIQUE values in column, and does not allows NULL values.

Customer_ID |
Name |
Age |
Gender |
|---|---|---|---|
101 |
Alice |
25 |
F |
102 |
Bob |
30 |
M |
103 |
Charlie |
28 |
M |
Primary Key:
Customer_IDEnsures each customer is uniquely identifiable.
2. Foreign Key (FK)#
A foreign key links one table to another. It creates a relationship between two or more tables, a primary key of one table is referred as a foreign key in another table. It can also accept multiple null values and duplicate values.

Orders Table
Order_ID |
Customer_ID |
Product |
Quantity |
|---|---|---|---|
5001 |
101 |
Laptop |
1 |
5002 |
102 |
Keyboard |
2 |
5003 |
101 |
Mouse |
1 |
Customer_IDhere is a foreign key connecting each order to the Customers table.Prevents creating an order for a non-existent customer.
3. Composite Key#
Sometimes, no single column uniquely identifies a row. Composite Key is a combination of more than one columns of a table. It can be a Candidate key and Primary key.

Enrollments Table
Student_ID |
Course_ID |
Grade |
|---|---|---|
S001 |
CSE101 |
A |
S001 |
MTH201 |
B+ |
S002 |
CSE101 |
A- |
S002 |
PHY110 |
B |
Neither
Student_IDnorCourse_IDalone is unique.Together
(Student_ID, Course_ID)form a composite key.Ensures a student cannot enroll in the same course twice.
4. Candidate Key#
A candidate key is any column (or set of columns) that could serve as a primary key. Candidate Key(s) an identify a record uniquely in a table and which can be selected as a primary key of the table.
It contains UNIQUE values in column, and does not allows NULL values.

Here, Empid, EmpLicence and EmpPassport are candidate keys.
Example: Employees Table
Employee_ID |
SSN |
Name |
|
|---|---|---|---|
E001 |
123-45-6789 |
Alice |
|
E002 |
987-65-4321 |
Bob |
|
E003 |
111-22-3333 |
Charlie |
Possible unique identifiers:
Employee_IDEmailSSN
Each is a candidate key.
One (e.g.,
Employee_ID) is chosen as the primary key.
Remember, Each table can have only one Primary key and multiple Candidate keys
PK-FK Relationships#
Relational databases use primary keys (PK) and foreign keys (FK) to maintain data integrity and model relationships.
Types of Relationships#
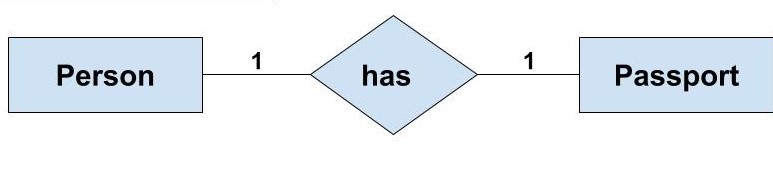
One-to-One (1:1): Each person has one passport; each passport belongs to one person.
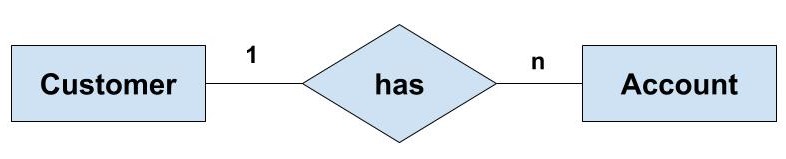
One-to-Many (1:N): A customer can have many orders; each order belongs to one customer.
Many-to-Many (M:N): Students enroll in many courses; courses have many students.
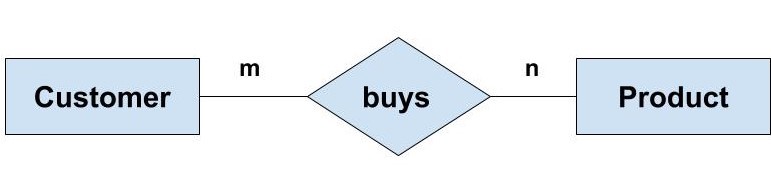
In this figure, each customer can buy more than one product and a product can be bought by many different customers.
Customers Table#
Customer_ID (PK) |
Name |
Age |
Gender |
|---|---|---|---|
101 |
Alice |
25 |
F |
102 |
Bob |
30 |
M |
103 |
Charlie |
28 |
M |
Orders Table#
Order_ID (PK) |
Customer_ID (FK) |
Product_ID (FK) |
Quantity |
|---|---|---|---|
5001 |
101 |
P100 |
1 |
5002 |
102 |
P101 |
2 |
5003 |
101 |
P102 |
1 |
Customer_IDis a foreign key referencingCustomers.Customer_ID.Product_IDis a foreign key referencingProducts.Product_ID.
Products Table#
Product_ID (PK) |
Product_Name |
Price |
|---|---|---|
P100 |
Laptop |
1000 |
P101 |
Keyboard |
50 |
P102 |
Mouse |
30 |
Passports Table (One-to-One Example)#
Passport_ID (PK) |
Customer_ID (FK) |
Expiration_Date |
|---|---|---|
P001 |
101 |
2030-12-31 |
P002 |
102 |
2031-06-30 |
P003 |
103 |
2030-09-15 |
Customer_IDis a foreign key referencingCustomers.Customer_ID.Each customer has exactly one passport.
Enrollments Table (Many-to-Many Example)#
Student_ID |
Course_ID |
Grade |
|---|---|---|
S001 |
CSE101 |
A |
S001 |
MTH201 |
B+ |
S002 |
CSE101 |
A- |
S002 |
PHY110 |
B |
Neither
Student_IDnorCourse_IDalone is unique.The combination
(Student_ID, Course_ID)forms a composite key.Students can enroll in many courses, and courses can have many students.
Relationships Overview#
From Table |
To Table |
Type |
Notes |
|---|---|---|---|
Customers |
Orders |
1:N |
One customer → many orders |
Products |
Orders |
1:N |
One product → many orders |
Customers |
Passports |
1:1 |
One customer → one passport |
Students |
Courses |
M:N |
Implemented via Enrollments table |
Key Points#
Primary Key (PK): Unique identifier for each record. Cannot be NULL.
Foreign Key (FK): Links a table to another table’s primary key. Maintains referential integrity.
Composite Key: Combination of columns used when a single column is not unique.
Candidate Key: Any column or combination of columns that could serve as a primary key.
Constraints: Rules to maintain data validity (e.g., NOT NULL, UNIQUE, CHECK, FOREIGN KEY).
The Role of SQL in Data Science#
Think of SQL as your conversation partner with the data. It’s a declarative language, which means you simply state your desired outcome, and the database handles the complex task of finding and organizing the data for you. This makes it incredibly efficient for handling massive datasets. A typical data science workflow using SQL might look like this:
Data Extraction: You use a SELECT query to pull a specific subset of data relevant to your project.
Data Wrangling: You perform initial cleaning, filtering (WHERE), and aggregation (GROUP BY) directly in the database.
Analysis: The prepared data is loaded into Python (often as a Pandas DataFrame) for more sophisticated analysis, modeling, and visualization.
Core SQL Commands: Your Essential Toolkit#
We have already learned that SQL is the standard language for managing and querying relational databases.
These core commands allow you to create tables, insert data, retrieve information, update records, and maintain data integrity.
Whether you are analyzing sales data, customer information, or product inventories, mastering these commands is essential for data-driven tasks.
Command |
Purpose |
Example |
|---|---|---|
CREATE TABLE |
Create a new table in the database |
|
INSERT INTO |
Adds new rows of data to a table |
|
SELECT |
Retrieves data from one or more tables |
|
WHERE |
Filters records based on a condition |
|
UPDATE |
Modifies existing data in a table |
|
DELETE |
Removes rows from a table |
|
DROP TABLE |
Deletes the entire table and all its data |
|
Notes:
CustomerIDis the primary key and usesAUTO_INCREMENTto generate unique IDs automatically.Always use
WHEREinUPDATEandDELETEto avoid modifying all rows by mistake.DROP TABLEpermanently deletes the table and its data, so use with caution.