Introduction to Machine Learning#
Imagine you were tasked with building a perfect Spam Filter in the 1990s. As a programmer, you would write thousands of manual rules:
IF email contains “FREE MONEY” OR “CLAIM PRIZE” THEN classify as SPAM.
This works for a day, but then spammers change “FREE MONEY” to “FR€€ M0N€Y.” You add new rules, but the spammers always win. The problem is too complex and changes too fast for fixed, explicit rules.
*The Machine Learning Solution: Machine Learning (ML) solves this by abandoning fixed rules. Instead of telling the computer how to classify spam, we show it a mountain of data—millions of emails already labeled as “Spam” or “Not Spam.”
The ML algorithm then learns the hidden patterns and correlations on its own: not just individual words, but the combination of words, the structure of the text, and even the sender’s metadata.
This is the core idea:
Instead of programming explicit rules, we let the computer learn patterns from data.
Section 1: Formal Definition: What is Machine Learning?#
Machine Learning (ML) is a subfield of Artificial Intelligence (AI) that focuses on developing systems that can learn from data and improve their performance on a specific task over time, without being explicitly programmed.for that task.
Definition: Machine Learning is the science of getting computers to learn and act like humans do, and improve their learning over time in autonomous fashion, by feeding them data and information in the form of observations and real-world interactions.
Key Idea: Instead of programming explicit rules, we let the computer learn patterns from data.
Think of it this way: instead of a traditional programmer writing a specific rule like “IF the email contains ‘prize’ and ‘claim now’ THEN classify as spam,” an ML algorithm is fed thousands of examples of spam and not-spam emails. It then learns the hidden patterns and rules on its own to make the classification.
The core idea can be summarized as:
Experience (E) → Task (T) → Performance (P)
A machine learns from experience (E) with respect to some task (T), and its performance (P) in the task improves.

Why Machine Learning?#
In traditional programming, we give the computer explicit rules to follow. However, some problems are too complex to define with simple rules — for example, identifying a cat in an image or predicting stock prices. Machine Learning (ML) helps solve such problems by learning patterns from data rather than following fixed instructions.
Traditional Programming vs Machine Learning#
Traditional Programming |
Machine Learning |
|---|---|
Rules + Data → Output |
Data + Output → Rules (Model) |
Example: Instead of writing rules to detect spam manually, we show the computer many examples of spam and not spam emails, and it learns the pattern itself.
Real-World Applications#
Recommendation Systems: Netflix suggestions, Amazon ‘Customers Also Bought…’
Natural Language Processing (NLP): Translation (Google Translate), Voice Assistants (Siri, Alexa).
Computer Vision: Facial recognition, self-driving cars.
Prediction: Stock market forecasting, predicting equipment failure.
Banking → fraud detection
Key Terminology You Must Know#
Before we look at the process, let’s establish the fundamental vocabulary.
Term |
Analogy |
Technical Description |
|---|---|---|
Feature (or Attribute) |
The ingredients of a recipe. |
An input variable used to make a prediction. Example: Square footage, number of bedrooms, and location for a house. |
Label (or Target) |
The final dish price. |
The output variable that we are trying to predict or classify. Example: The actual selling price of the house or whether a photo contains a dog. |
Model |
The trained chef. |
The algorithm (the mathematical function) that has been trained on the data to find the relationship between the features and the label. |
Training |
Practicing the recipe. |
The process where the algorithm learns the optimal parameters by being fed the training data (Features + Labels). |
Prediction (or Inference) |
Guessing the cost of a new recipe. |
The output generated by the trained model when given new, unseen data (Features only). |
Section 2: How Machines Learn#
The Core Idea#
ML algorithms use data to find patterns, and then use those patterns to make predictions.
For example:
Input (Feature) |
Output (Target) |
|---|---|
Hours studied = 1 |
Score = 50 |
Hours studied = 2 |
Score = 60 |
Hours studied = 3 |
Score = 70 |
From this, the model learns that more hours studied → higher score, and can predict the score for 4 hours studied.
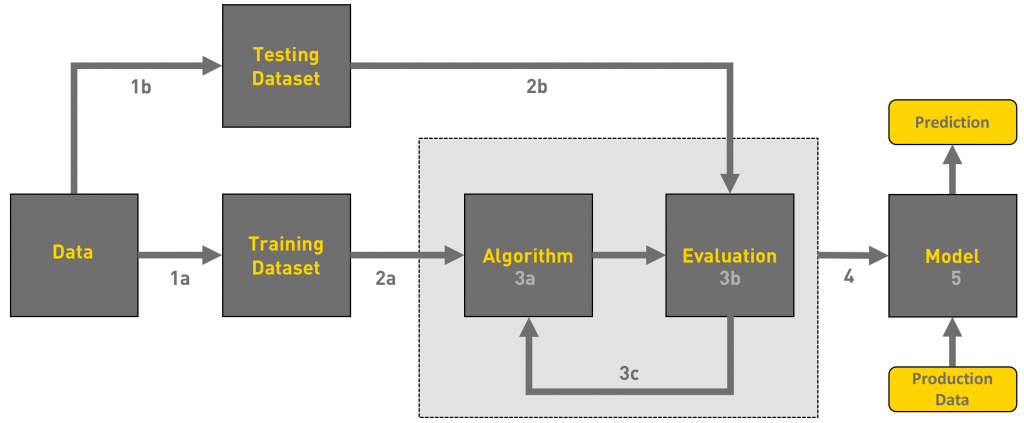
For this problem, the ML Process Flow will be#
Collect Data (Gathering the Hours Studied vs. Score pairs).
Prepare Data (Cleaning errors, normalizing features).
Train Model (The algorithm learns the \(\text{Score} \approx 10 \times \text{Hours}\) pattern).
Evaluate Model (Testing the model’s predictions on new, unseen data).
Deploy (Using the model to predict a score for the next student)
We will discuss about this more later.
Section 3: Types of Machine Learning#
ML problems are categorized based on the data they use and the goal they pursue. The Three Main Types of Machine Learning are -
Type |
Data Type |
Goal |
|---|---|---|
Supervised |
Labeled |
Predict output |
Unsupervised |
Unlabeled |
Discover structure |
Reinforcement |
Sequential |
Maximize reward |

3.1. Supervised Learning#
In supervised learning, the algorithm learns from labeled data, meaning we already know the correct answers.
The machine is “supervised” because all the training data is labeled—it includes the correct answers.
Goal: Learn a mapping from Features (X) to Labels (y).
Data: Input data with corresponding correct output labels.
Tasks: Examples:
Classification: Predicting a category (discrete value).
Examples: Spam/Not Spam, Cat/Dog, Good Loan/Bad Loan.
Regression: Predicting a continuous value (a number).
Examples: House Price, Temperature, Stock Price.
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Model Accuracy: {accuracy:.2f}")
3.2. Unsupervised Learning#
Unsupervised learning deals with unlabeled data, where the goal is to find hidden patterns or groupings.
The machine is “unsupervised” because the data is unlabeled—it has no correct answers.
Goal: Discover hidden patterns, structures, and relationships within the data on its own.
Data: Input data without corresponding output labels.
Tasks:
Clustering: Grouping similar data points together.
Example: Segmenting customers into different marketing groups (e.g., ‘High Spenders’ vs. ‘Occasional Buyers’).
Example: Grouping customers by purchasing habits
Dimensionality Reduction: Simplifying data by reducing the number of features.
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
X = load_iris().data
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
print("Cluster Centers:\n", kmeans.cluster_centers_)
3.3. Reinforcement Learning#
Reinforcement Learning is about learning through rewards and penalties — the model learns from its own actions to maximize total reward.
This type of ML involves an Agent interacting with an Environment.
Key Concepts:
Agent: The learner or decision-maker (e.g., a robot or game AI).
Environment: Everything the agent interacts with (e.g., game board, robot arena).
Action: Any move the agent can take.
Reward: Feedback received after an action (positive or negative).
Goal: Learn an optimal sequence of actions to maximize total reward.
Mechanism: The agent performs an action, receives a reward for a good action or a penalty for a bad one, and adjusts its behavior (policy) accordingly to improve future decisions. Repeat until the agent achieves an optimal strategy.
Examples of Reinforcement Learning:
Game AI: Training AI to play complex games like Chess, Go, or Atari.
Robotics: Controlling autonomous robots.
Robot Learning: Teaching a robot to walk or balance.
Continuous Learning: A game-playing AI improving over time as it gains experience.
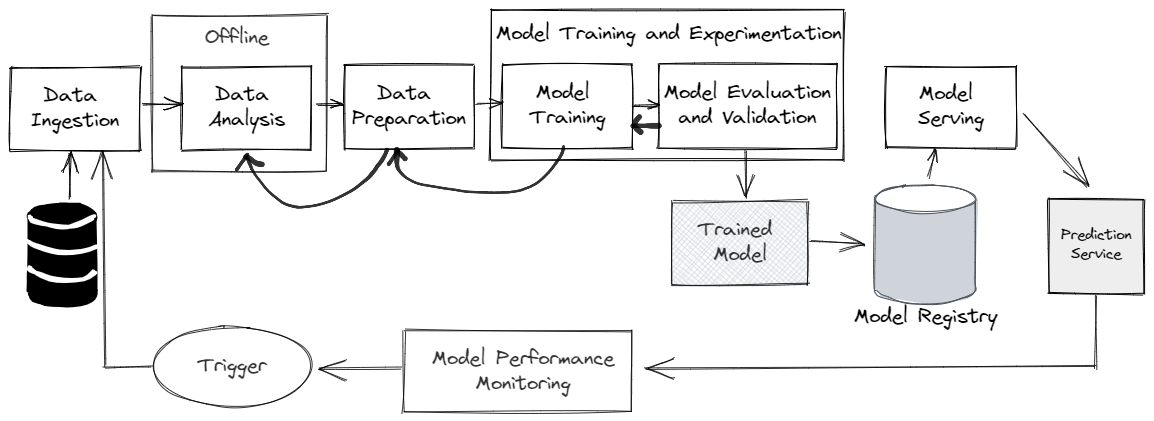
Section 4: The Machine Learning Workflow (Focused on Supervised)#
This is the standard process for building a predictive model.
Steps in the Workflow#
Collect Data: Gather a relevant dataset (Features and Labels)from sensors, databases, or APIs.
Data Cleaning: Handle missing values, duplicates, and outliers.
Feature Engineering: Select or create the most important variables.
Split Data: Separate the data into two parts:
Training Set: Used to teach the model. (~70-80% of data)
Test Set: Used to evaluate the model on unseen data. (~20-30% of data)
Choose Model: Select an appropriate algorithm (e.g., Linear Regression, Decision Tree, Neural Network).
Train Model: Feed the Training Set to the algorithm using the
.fit()method. The model learns the pattern.Evaluate Model: Use the trained model to make predictions on the Test Set and calculate its accuracy or error (the performance \(P\)).
Deploy: Once the model is satisfactory, integrate it into a real-world application or production system to make live predictions.