Unsupervised Learning: Discovering Patterns Without Answers#
A Different Kind of Learning#
So far, most of our machine learning tasks follow a familiar pattern:
Inputs (features)
Outputs (labels)
The model learns a mapping from input → output. This is called supervised learning. But now consider a different situation.
You are given a dataset with many data points and features—but no labels. No correct answers. No categories. Just raw data. This raises an important question:
Can we learn something meaningful just from the structure of the data itself?

Figure: Unsupervised learning groups unlabeled data into patterns based on similarity. Source: MathWorks
This is where unsupervised learning begins.
2. The Problem of Too Many Features#
Consider analyzing customer behavior with features like:
Age
Income
Purchase frequency
Website activity
Now scale this to:
50, 100, or even 500 features
We quickly face challenges:
Visualization becomes impossible
Computation slows down
Many features are redundant or noisy
Relationships become hard to interpret
The data exists in a high-dimensional space, beyond our intuitive understanding. So we ask:
Can we simplify the data while preserving its important information?
Part A: Dimensionality Reduction#
Dimensionality reduction addresses this challenge.
It reduces the number of features while preserving the most important structure.
Think of it like:
Summarizing a long story
Compressing an image
Less data, but same essential meaning
One of the most powerful techniques for this is: Principal Component Analysis (PCA)
The Curse of Dimensionality#
Before PCA, we must understand why high dimensions are problematic.
The Curse of Dimensionality#
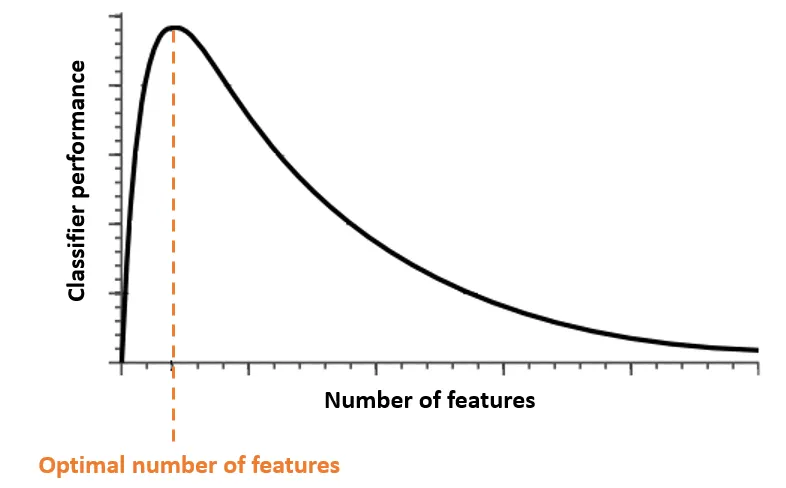
Figure: Hughes Phenomenon: Adding features helps initially, but too many features with limited data reduces performance. Source: Medium
As dimensions increase:
1. Data Becomes Sparse#
Points spread far apart, making the space mostly empty.
2. Distance Becomes Less Meaningful#
Nearest and farthest points become similar
Hard to distinguish similarity
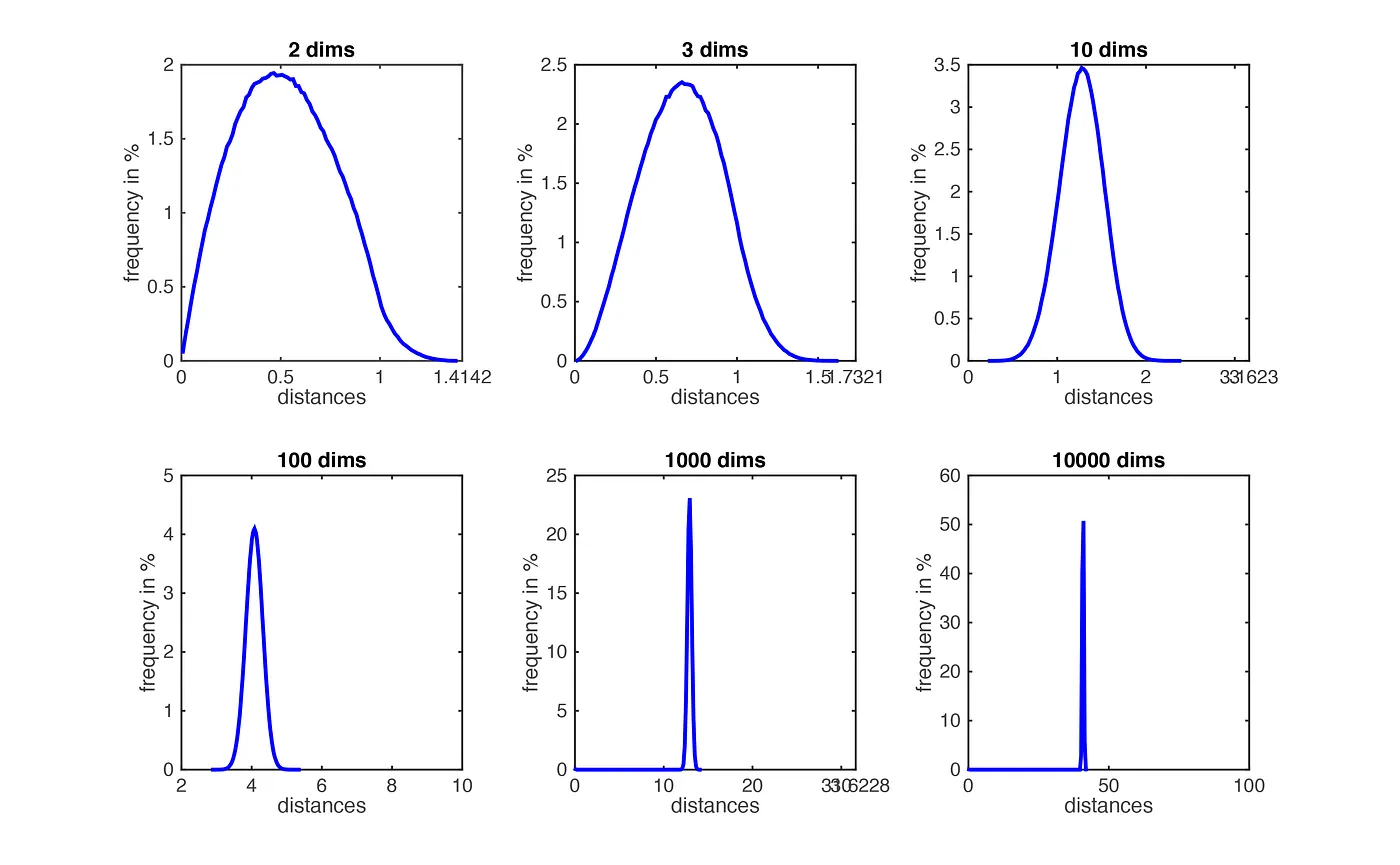
Figure: Distances lose meaning as dimensionality increases. Source: Medium
3. More Data is Required#
High dimensions require exponentially more data to learn effectively.
4. Noise and Redundancy Increase#
Irrelevant features
Correlated features
Added noise
Intuition#
2D → easy to understand
3D → harder
100D → nearly impossible to reason about
High-dimensional space behaves very differently from what we expect.
Why This Matters#
Because of these effects:
Model performance can degrade
Computation becomes inefficient
Interpretation becomes difficult
This is why we use dimensionality reduction
Reduce complexity while preserving structure
And one of the most important tools for this is: PCA