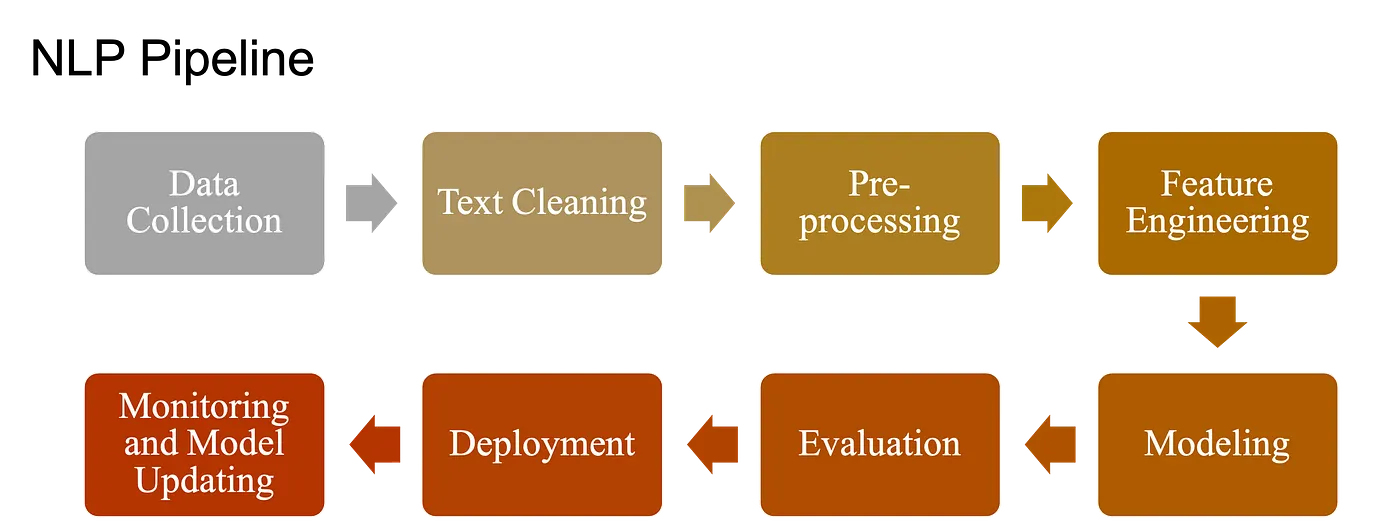
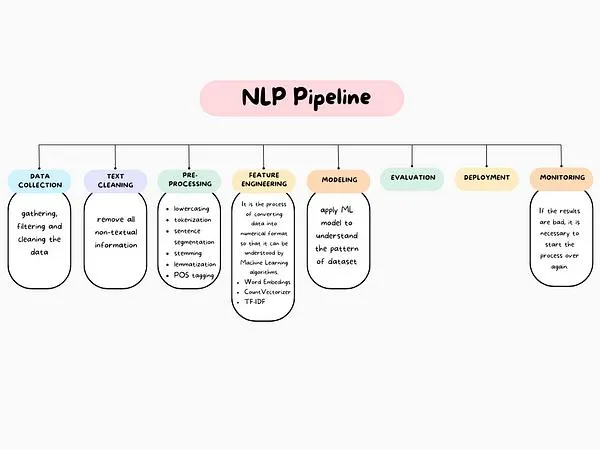
20.4 Fundamental NLP Tasks: Pipeline of NLP#
NLP covers a broad range of tasks. Some are foundational building blocks; others are application-focused. The Natural Language Processing (NLP) pipeline includes:
Raw Data (documents/text) Collection
Text Preprocessing
Basic Preprocessing: Text cleaning, Tokenization, Stemming etc.
Advanced Preprocessing: POS tagging etc.
Feature Extraction/Engineering
ML Modeling
Evaluation, Deployment and Monitoring

20.4.1 Data acquisition / raw data collection#
The first step in NLP is to obtain the raw text data in the form of documents, such as tweets, articles, reviews.
Basic Preprocessing:#
20.4.2 Text preprocessing#
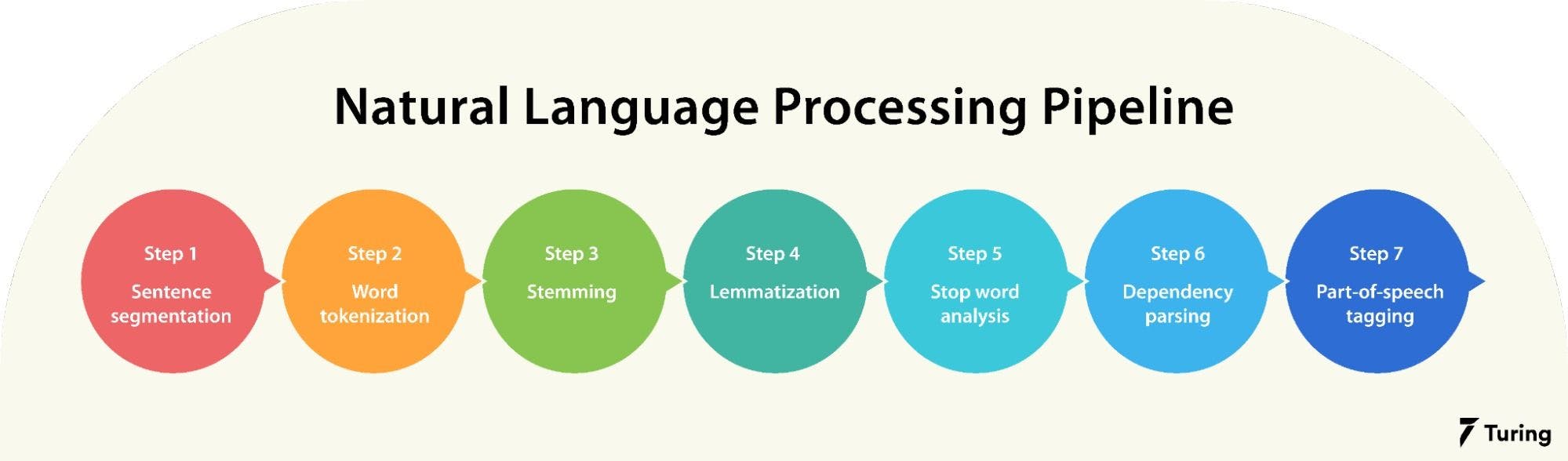
Before analysis, raw text must be cleaned and structured. That is why, in this step, the raw text is pre-processed by performing various operations such as tokenization, stop-word removal, stemming, and lemmatization, etc. This step is important as it helps to clean and normalize the data, making it easier to work.
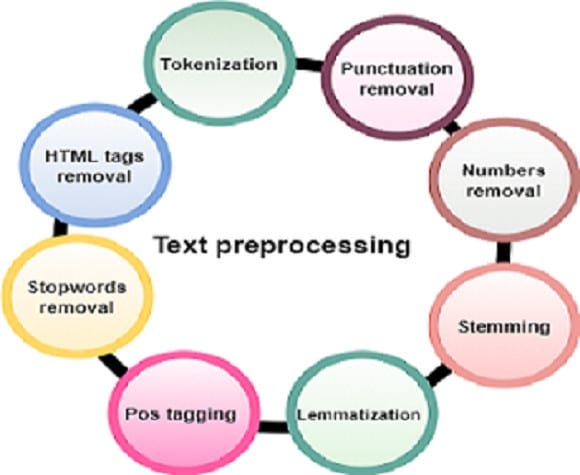
Text Cleaning: Removing noise, unwanted symbols, and irrelevant data.
Tokenization: Splitting text into words or subwords (making it easier for machines to process). Example: “I love NLP!” → [“I”, “love”, “NLP”, “!”]

There can be different type of tokenizations:
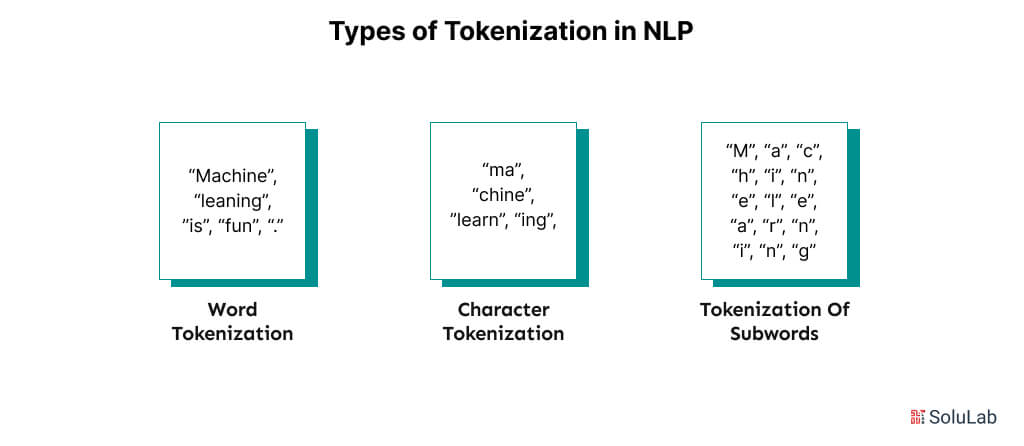
Stopword Removal: (Filtering out common words (e.g., “the,” “is”)) It involves identifying and removing common words such as “the”, “a”, “an”, “and”, “of”, that are unlikely to carry significant meaning in the text. These words are commonly referred to as “stop words” because they can be “stopped” or removed without affecting the overall meaning of the text.

Stemming & Lemmatization: Reducing words to their base forms (e.g., “running” → “run”).
Stemming: Remove affixes from a word to get base form (stem) of a word (stem might not be a lexicographically correct word). Example: “running” → “run” (rough cut). Good for search engines and simple tasks.
Lemmatization: Find lemma (dictionary form) of a inflected word (a lemma is always a lexicographically correct word). Example: “running” → “run” (dictionary-based, more precise). Best for tasks where meaning and context are important, like text classification and sentiment analysis.
Lowercasing and Normalization: Ensuring consistent text representation.
Handling Punctuation & Numbers:: Remove or normalize.
Spell Correction: Fix typos (“NLP is awsome” → “awesome”).
Special Character Removal: Remove punctuation (e.g., “Hello!” → “Hello”), numbers, emojis (or converting emojis into textual descriptions), HTML tags (e.g., “good” → “good”), and other non-alphabetic symbols. Extra spaces, tabs, and formatting characters are also cleaned to ensure uniform text.
Advanced Preprocessing:#
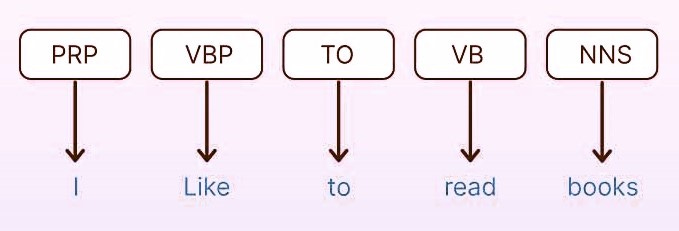
Part-of-Speech (POS) Tagging: is the process of assigning grammatical labels (lexical category) to each word in a sentence, such as noun, verb, adjective, or preposition. For example, in the sentence “The quick brown fox jumps over the lazy dog,” the words would be tagged as follows: “The” as a determiner, “quick” and “brown” as adjectives, “fox” and “dog” as nouns, “jumps” as a verb, and “over” as a preposition.
Some Common POS Tags: NN (Noun), VB (Verb), JJ (Adjective), RB (Adverb), PRP (Pronoun), IN (Preposition) and DT (Determiner).
Why It Matters:
Helps machines understand sentence structure (grammar).
Essential for lemmatization (reducing words to their base forms).
Improves text analysis in tasks like parsing, translation, and sentiment analysis.
Named Entity Recognition (NER): Finding names of people, organizations, locations, etc.
Dependency Parsing: Understanding grammatical relationships between words.