2. Collaborative Filtering Recommender System#
Collaborative filtering recommends items based on patterns of user behavior, such as ratings, clicks, purchases, or views.
Unlike content-based filtering, it does not use item features (e.g., genre, keywords). Instead, it relies on the idea:
Users who behaved similarly in the past may like similar items in the future.
How is Collaborative Filtering Different from Content-Based Filtering?#
Method |
Main Idea |
Uses Item Features? |
Uses Other Users? |
|---|---|---|---|
Content-Based Filtering |
Recommend items similar to what the user liked before |
Yes |
No |
Collaborative Filtering |
Recommend items based on similar users/items |
No |
Yes |
Content-based filtering uses item features while on the other hand Collaborative filtering uses user–item interaction patterns (matrix).
2.1 User-Based Collaborative Filtering (User–User CF)#
User-based collaborative filtering asks:
“Who else has similar taste as me?”
It finds the k most similar users (neighbors) and recommends items those users liked that the target user has not seen.
“Find people who think like you, then recommend what they loved.”
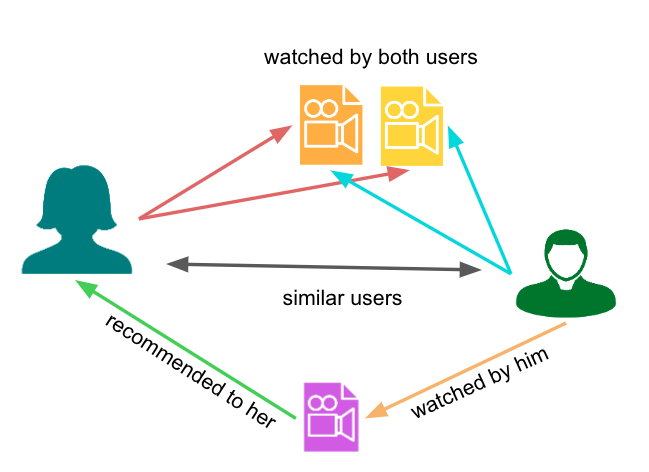
Figure: Illustration of a User-Based Collaborative Filtering recommender system. Source: Medium.
Key Observation:: We do not use item features (like genre). We only use rating patterns.
Similarity Measures#
Similarity between users is computed using:
Pearson Correlation#
Intuition#
Measures linear relationship
Removes rating bias (mean-centering)
Focuses on relative preferences
Why Pearson over Cosine?#
Pearson handles user rating bias. Example:
Alice rates everything 4–5
Bob rates everything 1–2
But both like the same movies
Pearson → identifies them as similar
Cosine → may treat them as different
Example:
Cosine Similarity: Cosine compares the raw vectors (no mean adjustment).
Alice = [5, 5, 4]
Bob = [2, 2, 1]
Even though the pattern is similar, the magnitudes are different, so cosine may not fully capture their similarity.
Pearson Correlation: Pearson first subtracts the mean:
Alice mean = 4.67 → [0.33, 0.33, -0.67]
Bob mean = 1.67 → [0.33, 0.33, -0.67]
Now they are identical after normalization
Pearson → similarity ≈ 1 (very similar)
So we can say:
Cosine similarity compares absolute values
Pearson correlation compares relative preferences (after removing bias)
Use cosine similarity → item features / embeddings
Use Pearson correlation → user ratings
Algorithm#
Construct a user–item rating matrix
Compute similarity between users (on commonly rated items)
For a target user, find k nearest neighbors
Predict ratings using a weighted average of neighbors’ ratings
Recommend items with the highest predicted ratings
Example#
User |
Movie A |
Movie B |
Movie C |
|---|---|---|---|
User 1 |
5 |
4 |
? |
User 2 |
5 |
4 |
5 |
User 3 |
1 |
2 |
1 |
User 1 ≈ User 2 → similar preferences
Recommend Movie C to User 1
Important Clarification: In user-based collaborative filtering, we compare:
one user’s rating pattern
withother users’ rating patterns
We do not use item features.
Advantages#
The intuition is powerful; it enables serendipitous discovery beyond your existing taste profile.
No need for item features
Can recommend new and diverse items
Captures collective intelligence of users
But it’s expensive to compute, since comparing every user pair scales as O(N²).
Disadvantages#
Requires sufficient user interaction data
Cold start problem (new users/items)
Computationally expensive (can scale as O(N²))
Similarity unreliable with sparse ratings
Key Insight: User-based collaborative filtering works best when we have:
Many users
Sufficient rating history
It answers: “What did similar users like that this user hasn’t seen yet?”
2.2 Item-Based Collaborative Filtering (Item–Item CF)#
“Find movies that are always rated the same way by the same people, then use that.”
Item-based collaborative filtering flips the perspective: instead of finding similar users, it finds similar items based on user interaction patterns.
At recommendation time, it looks at what a user has already rated, finds items most similar to those, and recommends them.
The Key Idea:
“Which items are similar to the ones this user liked?”
“If you liked this item, you may also like similar items.”
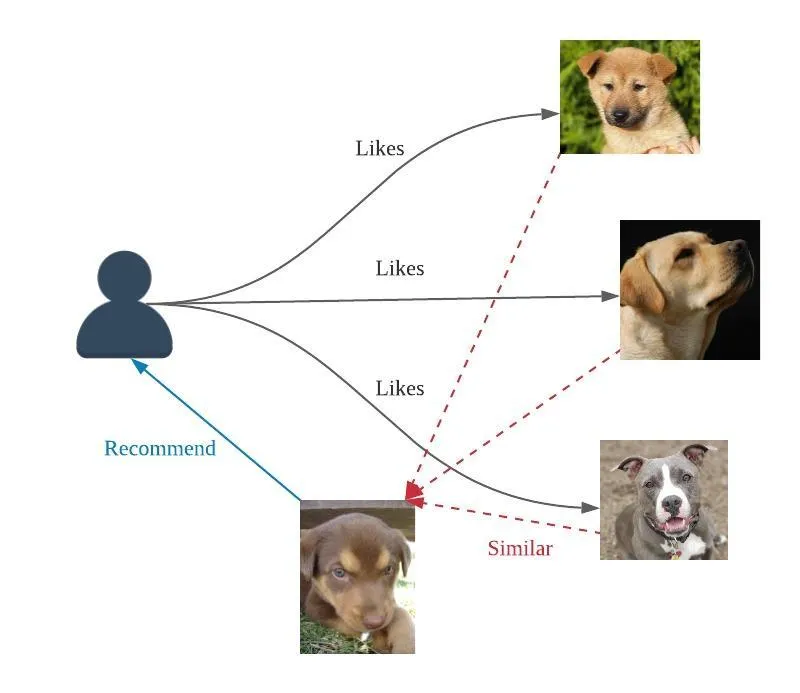
Figure: Illustration of a Item-Based Collaborative Filtering recommender system. Source: Medium.
This is what Amazon uses (“customers who bought X also bought Y”).
Key Observation: We do not use item features; instead, we compute item similarity using user behavior (ratings, clicks, purchases) via cosine similarity or Pearson correlation.
Intuition: Two items are similar if many users interacted with both items in a similar way
Algorithm#
Construct a user–item rating matrix
Compute item–item similarity (compare columns using cosine or Pearson similarity)
For a target user and an unseen item, find items most similar to that item that the user has already rated
Predict the rating using a weighted average of the user’s ratings on similar items
Recommend items with the highest predicted scores
Predict how much a user will like an item based on how similar it is to items they already liked.
Example#
User |
Movie A |
Movie B |
Movie C |
|---|---|---|---|
User 1 |
5 |
4 |
? |
User 2 |
5 |
4 |
5 |
User 3 |
1 |
2 |
1 |
Movie A and Movie B have similar rating patterns across users
If a user liked Movie A, recommend Movie B
Important Clarification: In item-based collaborative filtering, we compare:
item rating patterns (columns)
withother item rating patterns
We are not comparing users directly.#
Advantages#
More scalable than user-based CF
Item similarities are more stable over time
Can be precomputed for faster recommendations
Works well in real-world systems (e.g., e-commerce)
Disadvantages#
Requires sufficient interaction data
Cold start problem for new items
Cold start = no data → no recommendation
Cannot recommend items with no prior interactions
Key advantage over User-Based: Item similarity is stable (Inception vs Interstellar don’t change relationship over time), so we can pre-compute it once and look it up cheaply. This is why Amazon and Netflix prefer item-based CF.
Key Insight: Item-based collaborative filtering works best when:
Items are relatively stable
There is sufficient user interaction data
It answers: “What items are similar to the ones this user already liked?”
Cold Start Problem in Collaborative filtering#
The cold start problem occurs when a recommender system has insufficient data to make reliable recommendations.
Types of Cold Start#
New User Problem
A new user joins the system
No history (ratings, clicks, purchases)
System doesn’t know their preferences
New Item Problem
A new item is added
No user interactions yet
System cannot recommend it
New System Problem
Entire system is new
Very little interaction data overall
Why it happens#
Collaborative filtering relies on:
user–item interactions
similarity between users/items
Without data → no similarity can be computed
Example: A new user signs up on Netflix and has not watched anything yet. System cannot recommend movies effectively
Some Common Solutions:
Ask users for initial preferences (onboarding questionnaire)
Use content-based filtering initially
Recommend popular/trending items
Use hybrid systems