Hypothesis Testing in Data Science#
A Story About Decisions, Evidence, and Uncertainty
Why Hypothesis Testing Exists#
Imagine you are a data scientist at a food delivery company. Your team launches a new recommendation algorithm to increase the average order value.
After one week:
Old system average order: $24.10
New system average order: $25.30
Your manager asks:
“Did the new system actually work?”
The number increased, but that does not prove the algorithm caused the change.
Maybe customers simply ordered more that week.
Maybe there was a holiday.
Maybe the difference is just random fluctuation.
Hypothesis testing helps us answer this question.
It provides a structured way to decide whether an observed change reflects a real effect or ordinary variation.
The Core Idea#
Hypothesis testing is a decision-making framework under uncertainty.
We begin with a default assumption: that nothing has changed, and evaluate whether the observed data are unlikely enough to challenge that assumption.
This is similar to a courtroom:
A defendant is presumed innocent
Evidence must be strong to establish guilt
In statistics:
Default assumption → no effect
Strong evidence → reject that assumption
Formal Definition#
Hypothesis testing is a statistical method used to make inferences about a population based on sample data by evaluating competing claims (hypotheses) and determining whether the observed sample evidence is sufficiently unlikely if the null hypothesis is true.
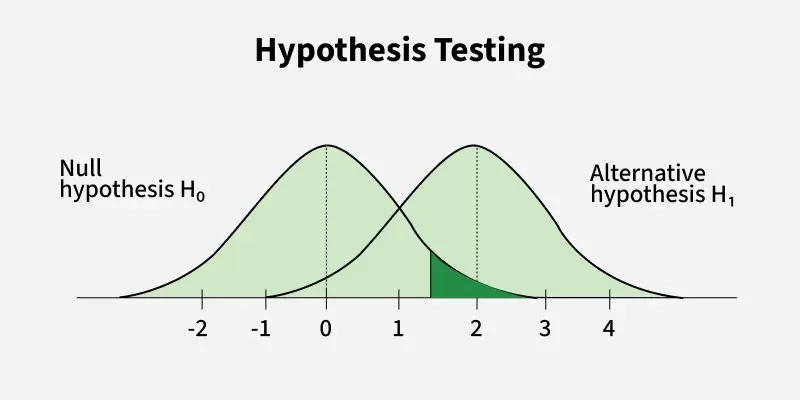
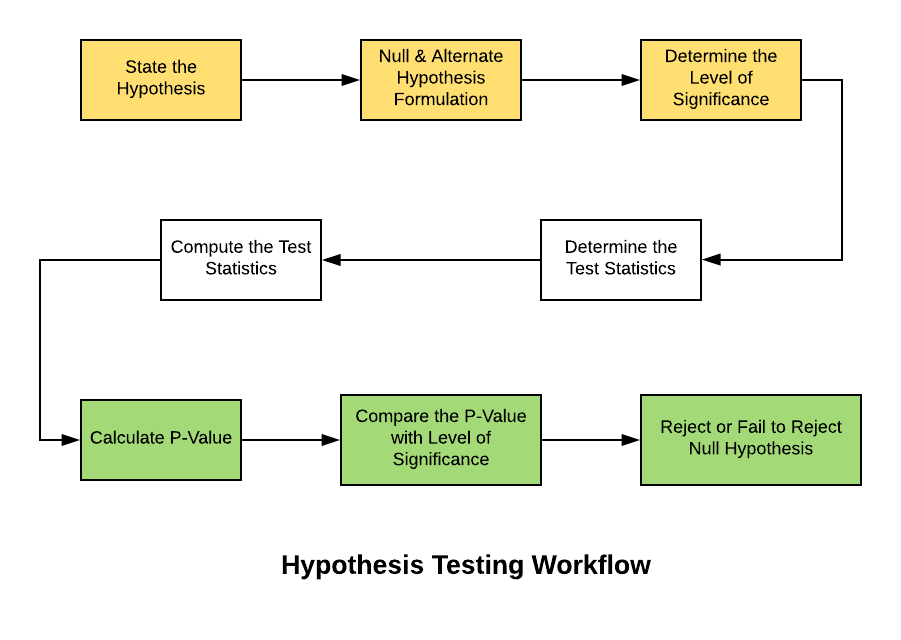
The overall logic of hypothesis testing can be visualized as a structured decision process:
|
|
Figure: Visual overview of the hypothesis testing decision process.
Both diagrams illustrate the structured sequence of statistical inference: defining hypotheses, selecting a significance level (α), computing a test statistic from sample data, and making a decision using either the critical value method or the p-value method to determine whether to reject or fail to reject the null hypothesis Sources: GeeksforGeeks and Vitalflux.
Steps in Hypothesis Testing#
The full workflow follows a structured sequence:
State the null and alternative hypotheses
Choose a significance level (α)
Select an appropriate statistical test and compute a test statistic
Apply a decision rule using either the critical value method or the p-value method.
Draw a conclusion and interpret the result in context
Both the critical value approach and the p-value approach lead to the same statistical decision.