Centrality Measures ( Node Importance)#
Not all nodes are equal. Some nodes connect many others; some nodes act as bridges and some nodes are closer to everyone.
Centrality measures quantify how important or influential a node is within a graph (or network).
Key insight: Different centrality metrics answer different questions about importance. A node can rank #1 on one metric and #5 on another.
We will cover three foundational measures:
Measure |
Core question |
Analogy |
|---|---|---|
Degree centrality |
How many direct connections? |
Popularity |
Closeness centrality |
How quickly can you reach everyone? |
Efficiency |
Betweenness centrality |
How often do you sit on the shortest path between others? |
Broker / gatekeeper |
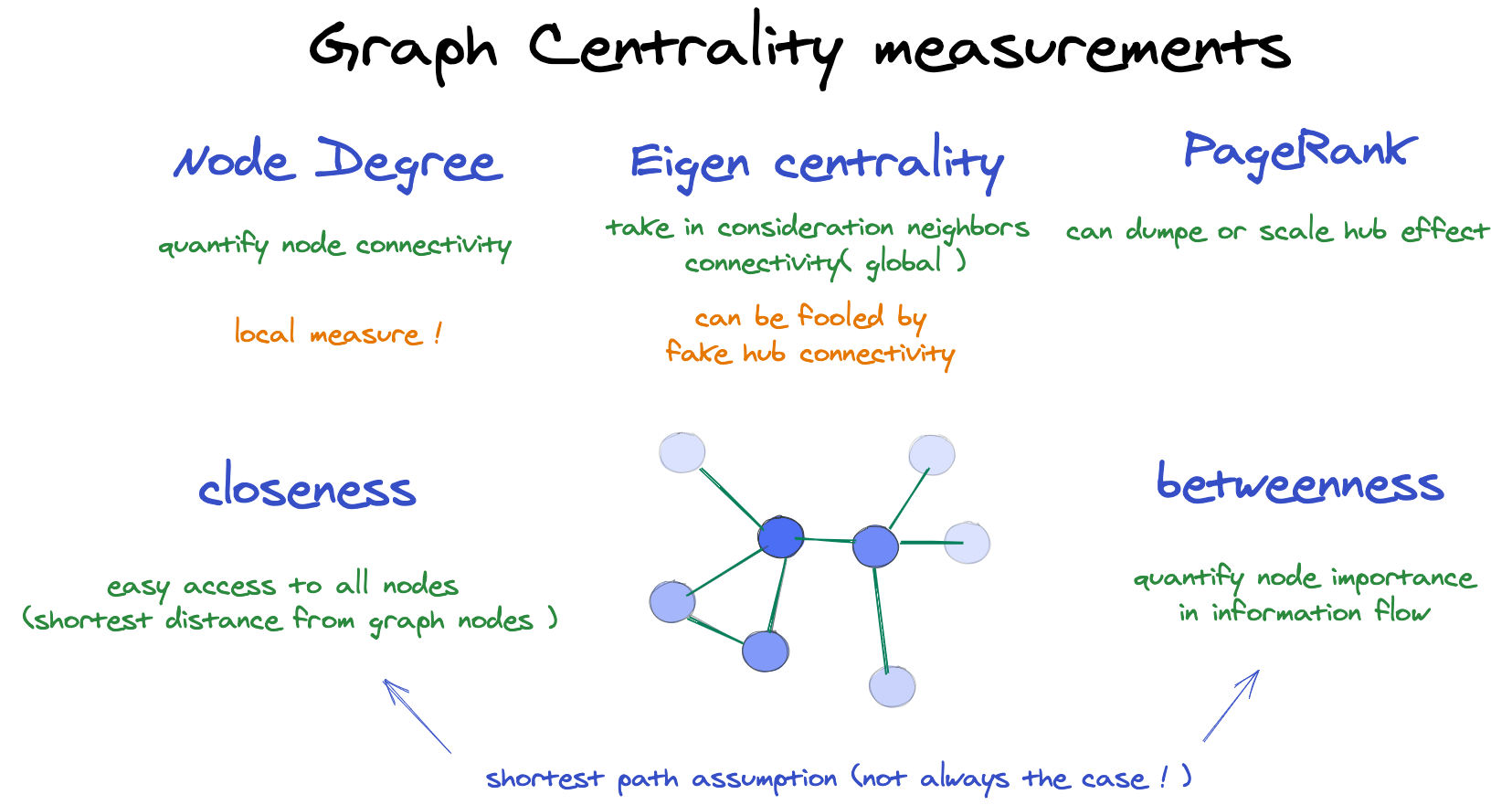
Illustration of different centrality roles in a network. Source: towardsdatascience.com
1. Degree Centrality#
The simplest measure. Measures importance based on number of direct connections.
A node’s degree centrality is its number of edges divided by the maximum possible edges.
Example: who has the most connections? Alice and Bob tie in our example. In a social network, a person with many friends has high degree centrality
where N is the total number of nodes.
High degree → directly connected to many nodes → “popular” or “well-networked”
Fast to compute: O(V + E)
Limitation: ignores the quality/importance of connections (a node connected to 10 isolated nodes vs. 10 hubs)
2. Closeness Centrality#
Measures how close a node is to all other nodes. It focus on how quickly a node can reach all others (based on shortest path). A node is close-central if its average shortest path to every other node is short.
Example: who can reach everyone else most quickly on average? A node that can quickly reach everyone (few hops) has high closeness.
where \(d(v, u)\) is the shortest path length between nodes v and u.

Nodes with high closeness are closer (shorter paths) to all others.Source: www.ebi.ac.uk
High closeness → information/influence spreads fast from this node
In a social network: the person who hears gossip first, or spreads news fastest
In a supply chain: the warehouse that can ship to any destination quickest
Complexity: O(V × (V + E)) using BFS from each node
3. Betweenness Centrality#
Measures how often a node acts as a bridge along the shortest path between two other nodes.
How often a node lies on shortest paths between other nodes. Identifies bridge nodes
Example: who is connected to other well-connected nodes? This is the core idea behind Google’s PageRank. A person connecting two groups has high betweenness
where:
\(\sigma_{st}\) = total number of shortest paths from s to t
\(\sigma_{st}(v)\) = number of those paths that pass through v
Notes: The normalized version divides by \((N-1)(N-2)/2\) so scores fall in [0, 1]. But in this course, we are not doing it.
High betweenness → gatekeeper / broker — controls information flow
Removing a high-betweenness node disrupts the network most
Used in: fraud detection (unusual intermediaries), infrastructure resilience, influence campaigns
Complexity: O(VE) (Brandes algorithm)
When to Use Which?#
Degree → quick measure of connectivity
Closeness → efficiency of communication
Betweenness → control over information flow
Eigenvector → influence in the network
Connection to Featurization#
Centrality measures are node-level features used in:
Recommendation systems
Social network analysis
Fraud detection
Graph-based machine learning
These features help models understand node importance and role
import networkx as nx
G = nx.Graph()
G.add_edges_from([
("You","Alice"),
("You","Charlie"),
("Alice","Bob"),
("Bob","David"),
("Charlie","Eve")
])
print("Degree:", nx.degree_centrality(G))
print("Closeness:", nx.closeness_centrality(G))
print("Betweenness:", nx.betweenness_centrality(G))
print("Eigenvector:", nx.eigenvector_centrality(G))
Degree: {'You': 0.4, 'Alice': 0.4, 'Charlie': 0.4, 'Bob': 0.4, 'David': 0.2, 'Eve': 0.2}
Closeness: {'You': 0.5555555555555556, 'Alice': 0.5555555555555556, 'Charlie': 0.45454545454545453, 'Bob': 0.45454545454545453, 'David': 0.3333333333333333, 'Eve': 0.3333333333333333}
Betweenness: {'You': 0.6000000000000001, 'Alice': 0.6000000000000001, 'Charlie': 0.4, 'Bob': 0.4, 'David': 0.0, 'Eve': 0.0}
Eigenvector: {'You': 0.5211200923556694, 'Alice': 0.5211200923556694, 'Charlie': 0.41790694813836154, 'Bob': 0.41790694813836154, 'David': 0.23192160753344954, 'Eve': 0.23192160753344954}